The common wisdom is PostgreSQL logical replication doesn’t support schema changes. I thought so too, until building PgCache forced me to understand the replication protocol in detail.
The reality is schema changes are transmitted in the stream, just not in a way that keeps read replicas synchronized. This distinction is crucial.
What the Documentation Says
The PostgreSQL documentation states plainly: “The database schema and DDL commands are not replicated.” This is technically accurate — ALTER TABLE, CREATE INDEX, and other DDL commands never appear in the logical replication stream.
But the statement is incomplete. It tells you what isn’t sent without clarifying what is.
If you stop at the headline claim, you’ll conclude that any system built on logical replication must handle schema changes entirely out of band. That’s true for DDL commands themselves. It’s not true for schema metadata.
What Appears in the Stream
What does appear in the stream are Relation messages. These are protocol messages that describe a table’s structure, including its name, columns, and column types. Most critically these messages arrive when data changes, not when the DDL runs.
The documentation describes this behavior:
Before the first DML message for a given relation OID, a Relation message will be sent, describing the schema of that relation. Subsequently, a new Relation message will be sent if the relation’s definition has changed since the last Relation message was sent for it.
If a table’s data never changes, no Relation message is ever sent for it.

The Timing Problem for Read Replicas
Schema changes only propagate to subscribers when data is modified. Here’s what actually happens:
- Developer executes:
ALTER TABLE users ADD COLUMN email VARCHAR(255) - The DDL runs on the origin database
- No message appears in the replication stream
- Eventually, an
INSERT,UPDATE, orDELETEis performed on theuserstable - PostgreSQL generates a Relation message with the updated schema
- The Relation message is sent before the DML operation
- Subscribers finally learn about the schema change
If data in that table is never modified, the schema change will never arrive.
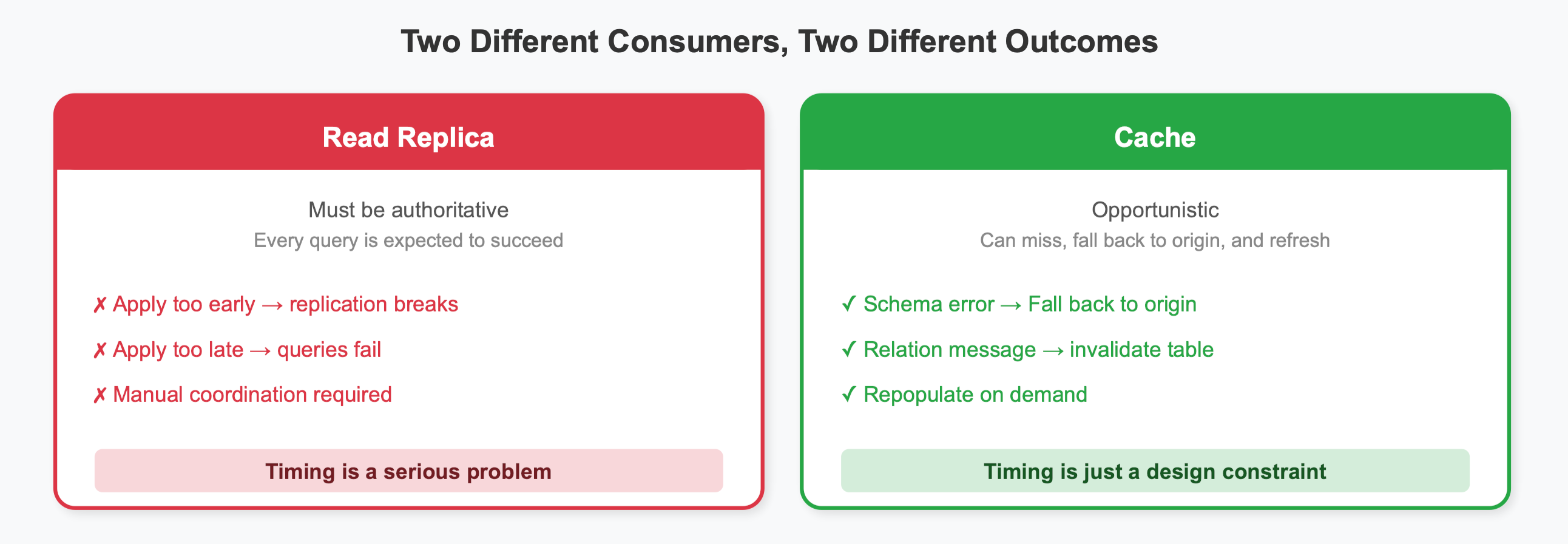
For read replicas, this creates serious coordination challenges. Schema changes must be manually applied to each replica, and the timing is critical. Apply changes too early, and the replication stream might send data that doesn’t match the replica’s schema, breaking replication. Apply changes too late, and application queries will fail when they reference columns that don’t exist on the replica yet.
Why Caches Can Tolerate This Timing
Caches operate fundamentally differently than read replicas. A read replica must be authoritative, every query is expected to succeed with the data and schema the replica has. A cache is opportunistic, it can miss, fall back to the origin, and refresh its understanding. This distinction transforms a serious limitation into an inconvenience.
How PgCache Implements This Approach
The insight that caches can afford to miss led to the approach used in PgCache. Rather than needing to maintain a perfectly synchronized schema like a read replica, the schema is treated as metadata that can be refreshed on demand.
When a query arrives, PgCache tries to process it from cache. If successful, it returns cached data. If there’s any error, including schema-related errors, it automatically fails over to the origin database. The query succeeds, and the result gets cached with the new schema.
PgCache learns about schema in two ways:
- For new tables: Proactively queries PostgreSQL to retrieve the initial schema.
- For known tables: Watches for
Relationmessages in the replication stream and compares them with the cached schema. When a change is detected, the entire table is invalidated and repopulated on demand.
Beyond Caching
The same principle applies to any system that tolerates temporary inconsistency: ETL pipelines that can reprocess when schemas change, analytics systems that refresh on mismatch, audit logs that don’t need real-time schema accuracy. If your system has a fallback mechanism, delayed schema metadata becomes a design constraint rather than a blocker.
For those building on logical replication, the Logical Streaming Replication Protocol documentation describes all message types in detail.